The Digital Revolution-2
Common Sense Algorithm Coming To A Computer Near You
Common Sense
I am meeting some friends in our local pizza eatery, and it is my turn to be the leader - this involves ordering everyone's favorites without asking them. And if I make the wrong order, I must do it again incurring the cost until I get it right without any help from my friends. This is the sort of game we play every weekend. We all know what everyone's preference is (stored in our phones). But the game is all about making the order without peeking on your phone while everyone is watching you.People take for granted the ability to deal with situations like these on a regular basis. In reality, in accomplishing these feats, humans are relying on not one, but a powerful set of universal abilities known as common sense. Despite being both universal and essential to how humans understand the world around them and learn, common sense has defied a single precise definition.
Common sense is unusually broad and includes not only social abilities, like managing expectations and reasoning about other people’s emotions, but also a naive sense of physics, such as knowing that a heavy rock cannot be safely placed on a flimsy plastic table. Naive, because people know such things despite not consciously working through physics (mathematics). Common sense also includes background knowledge of abstract notions, such as time, space, and events. This knowledge allows people to plan, estimate and organize without having to be too exact.
Artificial Intelligence
Intriguingly, common sense has been an important challenge at the frontier of AI since the earliest days of the field in the 1950s. Despite enormous advances in AI, especially in game-playing and computer vision, machine common sense with the richness of human common sense remains a distant possibility.There is now some consensus that we are approaching the nexus when computers start to learn tricks they weren’t designed to handle? Or develop deceptive behaviors that are hard to see through? Or come to truly “understand” the information they’re working on, raising philosophical questions about the boundaries between human and machine?
Serious AI researchers have long argued that questions such as these raise unreal expectations about their field and should stay in the realm of science fiction. Today’s AI systems, we are told, are boring number-crunchers, churning through massive data sets to draw their inferences.
So, what happens when the researchers themselves suggest that these sci-fi storylines are no longer as far-fetched as they once sounded?
Something significant has crept up in the AI world. Building ever-larger AI models have been all the craze for the past two years, as researchers have corralled huge computing resources and giant data sets to create ever more powerful systems.
Consequently, these systems have started to demonstrate a more generalizable intelligence that can be applied to several different tasks. This is important in AI. Until now, machine learning systems have been highly inflexible, and it has been hard to transfer a skill learned on one problem to another. With the huge size and the use of a new learning technique called transformers, this limitation seems to be falling away.
Flexible Machine Learning Algorithms
Their scale and adaptiveness could turn systems such as this into a new base layer of intelligence — what the Stanford researchers call foundation models. Developers working on specific applications of AI in, say, law or healthcare wouldn’t need to reinvent the wheel: they could call on a language system to provide the more generic capabilities. This idea need not be limited to language systems. Google’s MUM and similar “multitask” systems are already applying it to images. They could be followed, the researchers suggest, by a general-purpose reasoning capability, a flexible robotics model, and an AI that has mastered interaction with humans.
Other practical application
Spotting Newly formed craters on Mars
To identify newly formed craters on Mars, scientists will spend about 40 minutes analyzing a single photo of the Martian surface taken by the Context Camera on NASA's Mars Reconnaissance Orbiter (MRO), looking for a dark patch that wasn't in earlier photos of the same location.If a scientist spots the signs of a crater in one of those images, it then has to be confirmed using a higher-resolution photograph taken by another MRO instrument: the High-Resolution Imaging Science Experiment (HiRISE).
This method of spotting new craters on Mars makes it easy to determine an approximate date for when each formed — if a crater wasn't in a photo from April 2016 but is in one from June 2018, for example, the scientists know it must have formed sometime between those two dates. By studying the characteristics of the craters whose ages they do know, the scientists can then estimate the ages of older ones. This information can improve their understanding of Mars' history and help with the planning of new missions to the Red Planet.
The problem: this is incredibly time-consuming
The MRO has been taking photos of the Red Planet's surface for 15 years now, and in that time, it has snapped 112,000 lower-resolution images, with each covering hundreds of miles of the Martian surface.To free scientists from the burden of manually analyzing all those photos, researchers trained an algorithm to scan the same images for signs of new craters on Mars — and it only needs about five seconds per picture. To speed it up, the researchers ran the AI on a supercomputer cluster at NASA's Jet Propulsion Laboratory (JPL).
With the power of all those computers combined, the AI could scan an image in an average of just five seconds. If it flagged something that looked like a fresh crater, NASA scientists could then check it out themselves using HiRISE. Now, no one can disparage the advantages AI plays in this scenario.
All Pervasive
The prospect of pervasive new base-layer intelligence like the ones mentioned earlier raises some obvious questions. Who should build and control them? And, given that they might become common building blocks for many of the world’s more specialized AI systems, what happens when something goes wrong?The second interesting feature of exceptionally large AI models, meanwhile, has been their apparent ability to spontaneously learn new tricks. This is where things get weird. GPT-3 produced a technique known as in-context learning to master unfamiliar problems — even though its developers didn’t teach it to do this and a smaller predecessor, built to the same design, didn’t think of the idea.
So-called emergent capabilities such as this are the big unknown of large AI models. What happens when the people who build a system can no longer anticipate the full powers it will develop? The results might be hugely beneficial if the computers come up with new ways to solve intractable problems that their makers haven’t thought of. But there is also an obvious downside to machines working things out for themselves.
For now, exactly where this may lead is still confined to the pages of science fiction. But with the race to build ever-larger AI models gathering pace, we may not have to wait long to find out.
The Corollary
Companies of all sorts use machine learning to analyze all sorts of information - people's desires, dislikes or faces. Some researchers are now asking a different question - How can we make colossal computer network machines forget?A nascent area of computer science dubbed machine unlearning seeks ways to induce selective amnesia in artificial intelligence software. The goal is to remove all traces of a particular person or data point from a machine-learning system, without affecting its performance.
If this comes to fruition, the concept could give people more control over their data and the value derived from it. Although users can in some situations ask companies to delete personal data, they are always in the dark about what algorithms their information helped tune or train. Machine unlearning could make it possible for a person to withdraw both their data and a company's ability to profit from it.
Although intuitive to anyone who has rued what they shared online, that notion of artificial amnesia requires some new ideas in computer science. Companies spend millions of dollars training machine-learning algorithms to recognize faces or rank social posts because the algorithms often solve a problem more quickly than human coders alone. And here is the kicker - once trained, a machine-learning system is not easily altered or even understood. A more conventional way to remove the influence of a particular data point is to rebuild the system from the ground up, a potentially costly exercise. The conundrum thickens are you still with us?
Read More
Talk To Us
Most Recent Technology News
From The BBC
What We Do
Being abreast with technology is a very tasking procedure especially if you are a small enterprise. We can take the load off or make it more bearable - making sure all the tools with regards to your site for updating dynamic content, branding and bespoke marketing responsive HTML5 emails are at your finger tips. Adding new functionalities as you grow is the default.Our Approach
We believe in utilizing the power and influence of the Internet to help clients grow their business. Building results-driven digital solutions that is leveraged on current methodology and technology. This synergy results in a platform with cutting-edge design, development, branding and marketing. However, if all the aforementioned is to be accomplished, you need people with the know-how and wherewithal to put it all together.
Why Choose US
Our strategic services provide customized, digital solutions to turn your business into an industry leader. Our team plan, design, and develop outstanding website solutions that are in tandem with current technologies. Responsive websites from a single code base. Thus, making scaling up and enhancement very flexible.
The platform called the internet, to all intents and purposes comprise of websites. These in turn, are made-up of individual pages with common hyper-links interspersed. In it default state, it is very much a visual medium. Hence, in the design of a web-page, foremost in the structure and layout construction must be the end goal - rendition in a web browser.
The interactions within a web-page interface and layouts can only be experienced as a whole not through fragmentations. That is why our design approach in creating bespoke responsive website is unique. Most agencies will present you during the initial stages of design and deliberations, with mock-ups. We do not think these processes and procedures serve any purpose because fragmentations will never provide or emulate anything close to the real thing. Here at Torometech, we use your initial brief to design an interface that will showcase all the salient features your services or products exhibit.
Recent Portfolio
Here is an eclectic display of recent work we have carried out with regards to website and graphic creations respectively.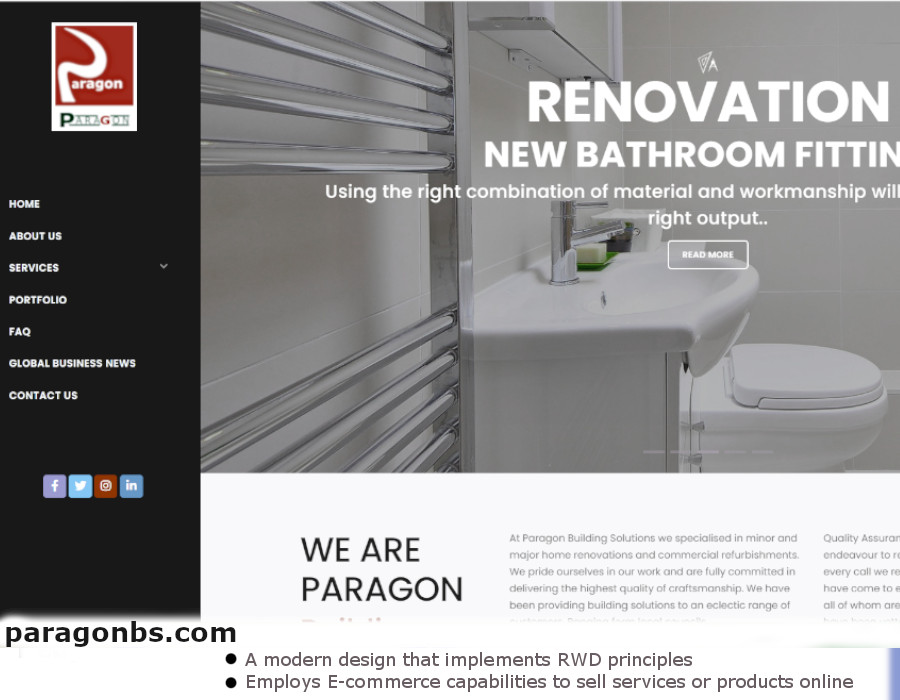

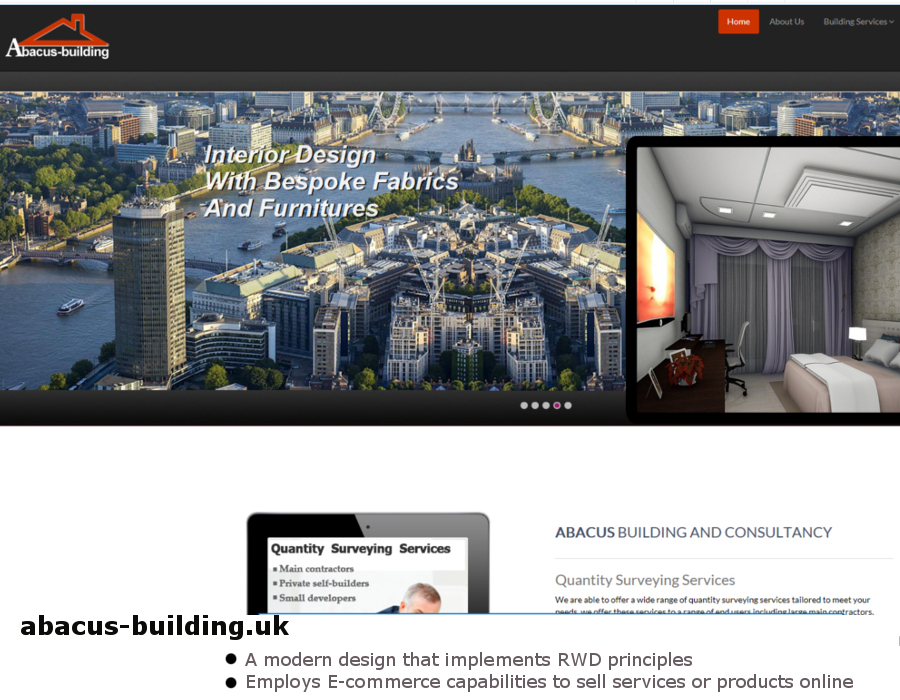
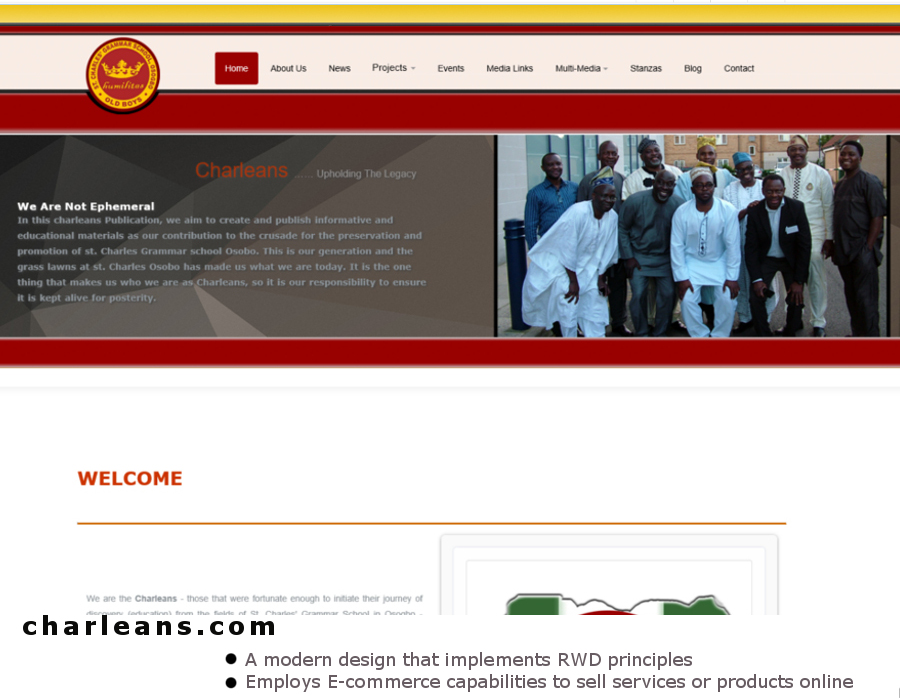
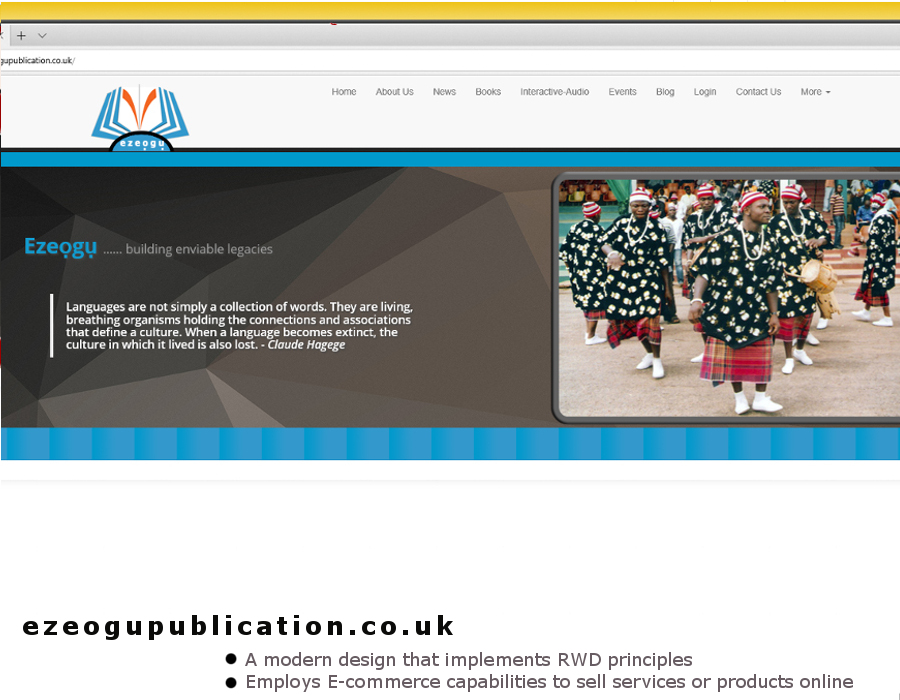







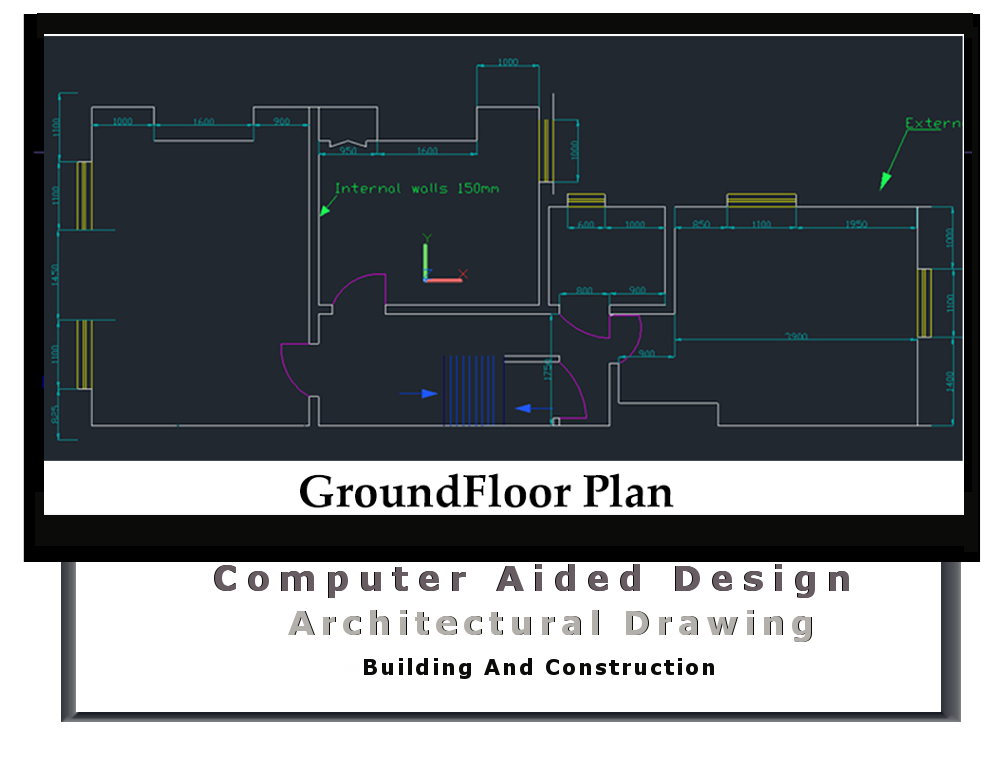
{kind=link}
Our Numbers
We are passionate about design & developments. We also understand the imperative of a website. It is not the frills of shiny vector graphics but the combination of a well throughout plan with and objective to accomplish
Our ServicesNo Of Clients
CUPS OF COFFEE
FINISHED PROJECTS
Lines Of Code